

The ZmGDB Genome Browser at PlantGDB
Overview
- What is ZmGDB? ZmGDB is a genome database and web display tool for Zea mays, featuring the xGDB genome browser interface. Both chromosomal (ZmGDB-Chrom) and BAC-based (ZmGDB-BAC) views of the genome are available.
- What does ZmGDB display? The ZmGDB (Chrom) genome browser displays an pseudomolecule assembly of the Accessioned Golden Path (AGP) maize Bacterial Artificial Chromosome (BAC) sequences. The ZmGDB (BAC) browser displays all Zea mays BACs from GenBank as well as other large (>10,000 nt) sequences deposited in GenBank. Both genome versions are splice-aligned to maize transcripts (EST and cDNA), transcript assemblies (PUT), and related-species predicted proteins. Additional tracks include microarray probes, Genome Survey Sequence assemblies (GSS), and Ds transposon flanking sequences (fDs) from the AcDs Tagging Project.
- How often are data updated?: The ZmGDB (Chrom) data will be updated as new versions of the assembly or significant changes in transcript data are available. ZmGDB (BAC) is updated dailing by an annotation pipeline that processes new BACs deposited to GenBank and displays new spliced alignment data on the ZmGDB browser and in the Protein Alignment Table (see below). Previous versions of a new BAC can still be viewed online, but are not available for BLAST analysis or gene structure annotation.
- What tools are available?. ZmGDB (Chrom) and ZmGDB (BAC) both provide tools for sequence analysis and retrieval (BLAST, GeneSeqer, GenomeThreader, Download from Region), described on the ZmGDB home page. In addition, all data used to create the ZmGDB database are also available for download; click "Download All Data" from the left menu of ZmGDB.
- Need more help? For comprehensive information on how to use genome browsers at PlantGDB, visit the Genome Browser Help pages and click on the right menu topics.
Protein Alignment Table (BAC version)
Overview
The Protein Alignment Table at ZmGDB displays a list of putative rice and sorghum homologs splice-aligned to each maize BAC, along with their coordinates and a functional description. The table is updated daily. Transposon and retrotransposon ORF annotations are filtered out by default, but can be viewed if desired. The table also shows BAC regions that match Ds transposon insertion flanking sequences (fDs), which are being generated as part of an NSF-funded project for genome-wide mutagenesis of maize using Ac/Ds transposons.
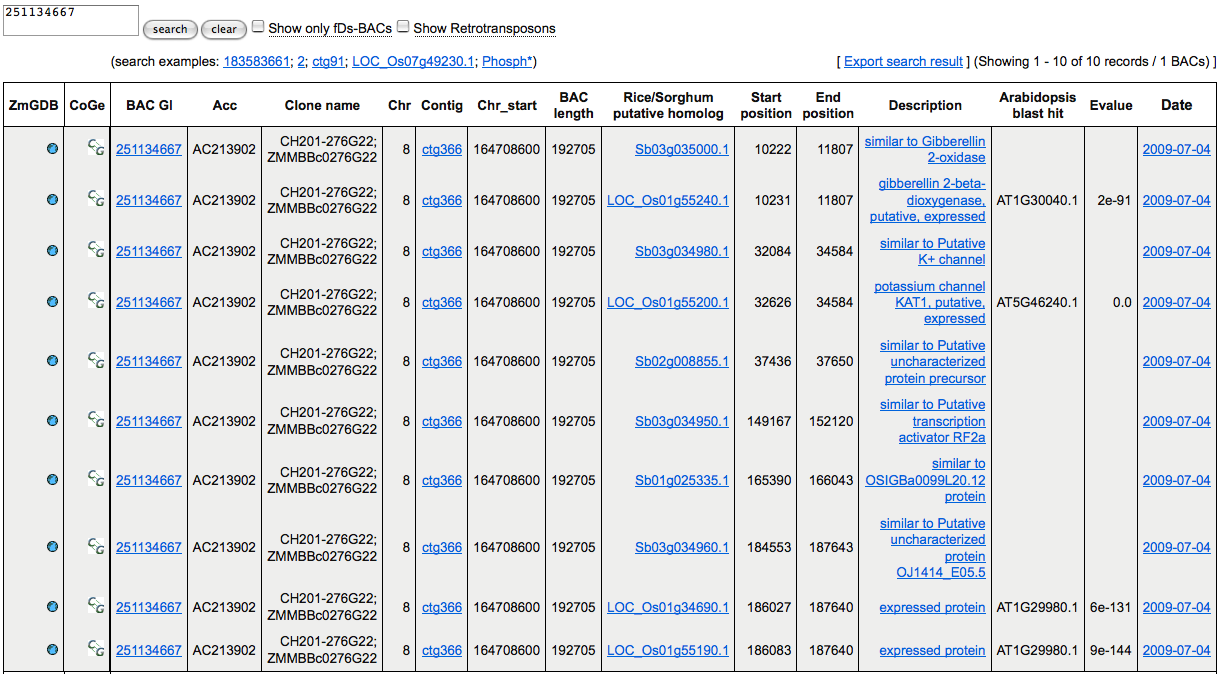
Table Columns
- ZmGDB - Link to ZmGDB's Genome Context View, centered on the current gene model
- CoGe Link to CoGe's synteny viewer (See below)
- BAC gi, Accession, Clone name - BACs in reverse chronological order by GI number/Accession/Clone (the date of upload to PlantGDB is shown in the last column). Alternating light and dark shading is used to distinguish successive BACs. Click gi (column 3) to show only data for that BAC.
- Chr / Contig /Chr_start - Chromosome and approximate chromosomal position (if known) are displayed. These data are compiled from the fpc_report.txt file at maizesequence.org. Click on any contig ID to display only BAC alignments within that fpc contig.
- Rice/Sorghum putative homolog - Rice (TIGR 5) and sorghum (Sbi1) gene model translations, representing putative orthologs to maize genes, are listed by locus ID for each BAC, in ascending order of alignment along the BAC sequence.
- Start position/End position - The start and end coordinates of each gene model protein alignment on the BAC.
- Description - The functional annotation for each gene model protein.
- Arabidopsis Blast hit) - Arabidopsis predicted proteins with BLASTp similarity to rice predicted proteins are displayed in column 13, along with E values.
Note 1: A single gene model per locus ID is displayed, although the ZmGDB browser may display multiple gene models (e.g splice variants) for many loci.
Note 2: Many Phase 1 BACs will consist of multiple unordered segments, so the linear order and directionality of loci shown here may be inaccurate.
Table Functions
Four types of functionality are built into the table: (1) Links for each BAC to the ZmGDB browser (Column 1); (2) Search box for retrieving records by ID or keyword (Search window); (3) Drill down search by clicking an ID or keyword (table cell links); and (4) Data filters (checkboxes).
- To launch a ZmGDB browser view of any BAC region, click on the corresponding BAC GI in column 1.
- To search for a specific BAC GI, rice putative homolog, or description, enter this information in the Search window and click "Search". Wild card searches using * are supported, as shown in the search example. Click "Clear Search" to clear all search parameters and filters.
- An alternative way to search for a rice putative homolog or description is to click on any table entry. This will search and display all instances of that entry across all BACs.
- View Retrotransposons (checkbox): In the default table view, the numerous alignments to rice retrotransposon proteins have been filtered out. Click "View retrotransposons" to view these alignments along with other annotated rice genes. Click "Clear Search" to restore default view.
- Show only fDs BACs (checkbox): see below.
Ds insertion sequences
Ds insertion flanking sequences (fDs) are genomic sequence tags derived from sequence flanking a Ds (Dissociation) transposon insertion event in maize. Thousands of such events have been "fixed" in a W22 inbred background as part of an NSF-funded project for genome-wide mutagenesis of maize using Ac/Ds transposons. The Ds element flanking sequences are cloned and sequenced, and the data is uploaded to GenBank at a rate of several hundred per month.
PlantGDB downloads fDs on a monthly basis and evaluates their alignment to BACs using BLASTn (95% identity, 95% coverage) in our daily pipeline. The resulting alignments are displayed on this table in context with rice and sorghum gene annotations, for the convenience of researchers interested in identifying potential mutants based on insertion in or near a well-defined locus. See AcDs Tagging project pages at PlantGDB for more details and other tools for searching the fDs collection.
The following are guidelines for viewing and search fDs tags in the BAC annotation table:
- Wherever an fDS matches a BAC sequence, the fDs clone name and coordinates (colored red) will be displayed in a table row. The fDs clone name will appear in column 2 in place of the BAC ID.
- If fDs coordinates overlap with a predicted protein alignment, the corresponding predicted protein ID and Description are displayed in the appropriate table cells. If there is no overlap with any protein alignment, these cells are left empty.
- To view an fDs alignment in the ZmGDB BAC genome browser, click on the BAC GI (column 1) in the appropriate table cell.
- Since fDs matches are infrequent, it is helpful to click "Show Only fDs BACs" to view only BACs that contain one or more fDs matches.
- If you want to identify an fDs match that putatively disrupts your favorite gene, first select "Show only fDs BACs", then do a search on the gene ID or annotation. Example: search within fDs BACS for "LOC_Os02g36700.1", a sucrose transporter. Result: fDs B.S05.0762_JSR01 overlaps a gene with this annotation on ZMMBBc0129L04
- Due to the prevalence of repeated DNA in maize, some fDs will have ambiguous localization. To view all BACs that show a potential match with a given fDs, click on the fDs ID or enter it as a search term. You can evaluate the relative quality of multiple BAC matches to an fDs using BLAST@ZmGDB.

Synteny Blocks
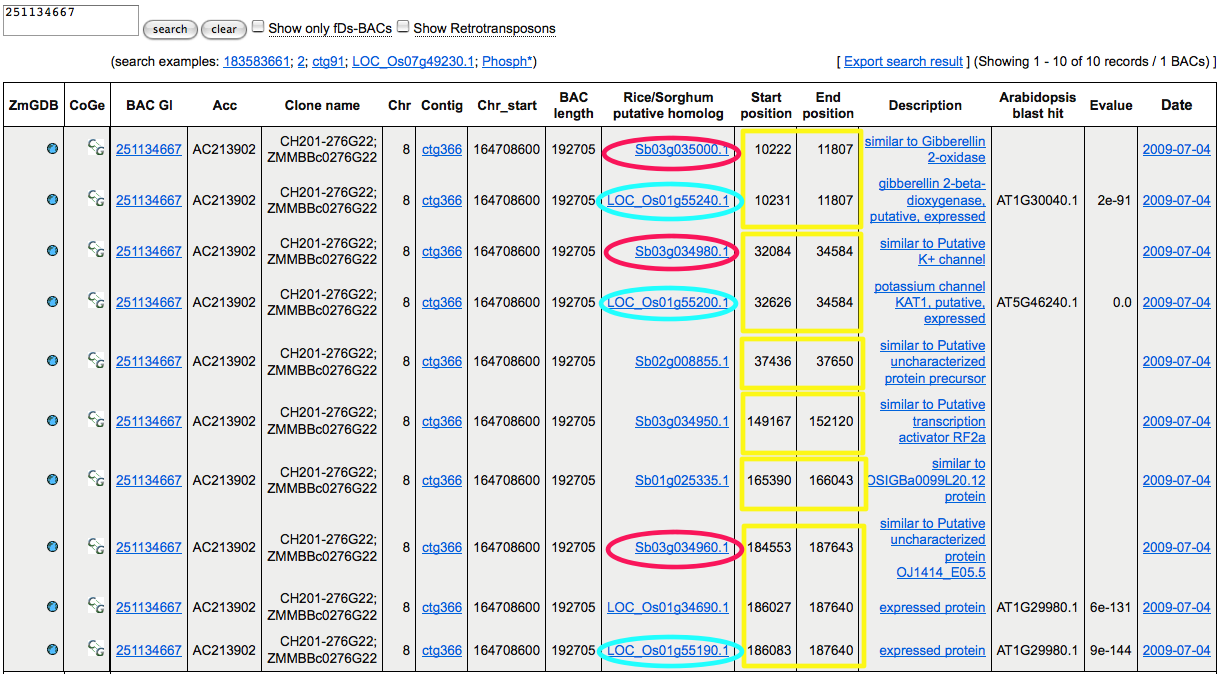
The Protein Annotation table can be used to identify blocks of colinearity between maize and rice or maize and sorghum. Since rice and sorghum gene models are named based on chromosome (e.g. Os_03g... or Sb_02g...) and relative order (e.g. Os03g08820.1 --> Os03g08850.1 --> Os03g08900.1 ) it is possible to infer microsynteny between rice and maize if you identify a contiguous set of closely-linked rice gene models aligned to a maize BAC. For example on the BAC listed below, there are multiple loci inferred by overlapping coordinates of splice-aligned proteins (yellow blocks). Inspection of the ID's to identify the chromosome and relative positions of each sorghum protein (red circles) or rice protein (blue circles) reveals evidence of microsynteny between maize and both species. See screenshot below.
To further explore potential microsynteny, click on the column 2 to view this BAC and syntenous genome(s) aligned to each other in CoGe's GEvo tool (described in the next section below).
Links to CoGe
The ZmGDB Protein Alignment Table can link to CoGe's powerful GEvo (Genome Evolution) tool for evaluating synteny across genomes. Using this feature you can create on-th-fly multigenome alignments, using sorghum and/or rice gene models that overlap with a selected maize BAC region as "seed" sequences. To try this, follow these steps using the Protein Alignment Table at ZmGDB:
- Locate a rice or sorghum protein of interest (representing a putative maize locus), using the Search feature or by browsing the table.
- Now click the CoGe icon link in column 2 of the table (see below).

- This launches a new GEvo page in CoGE, configured for a multiple genome comparison between the maize BAC and the model genome region selected.
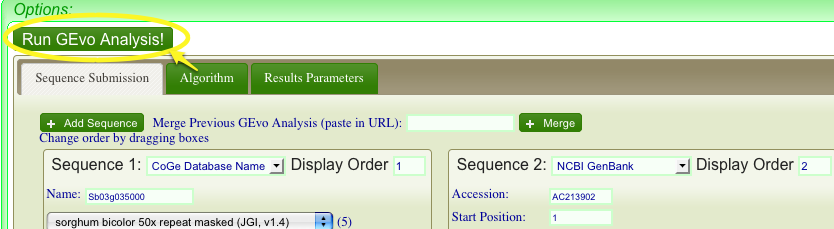
- If there are multiple model species loci that overlap the selected region, these will also be included in the GEvo multigenome page-- however if you only want to compare a subset of genome regions, use GEvo's "Sequence Options" to skip one or more sequences.
- Click "Run GEVo Analysis" at the top of the GEvo page (see above)
- GEVo will then initiate a real-time blastz (default) comparison of the two genomic regions (other options include tblastx, lagan, chaos, and dialign2).
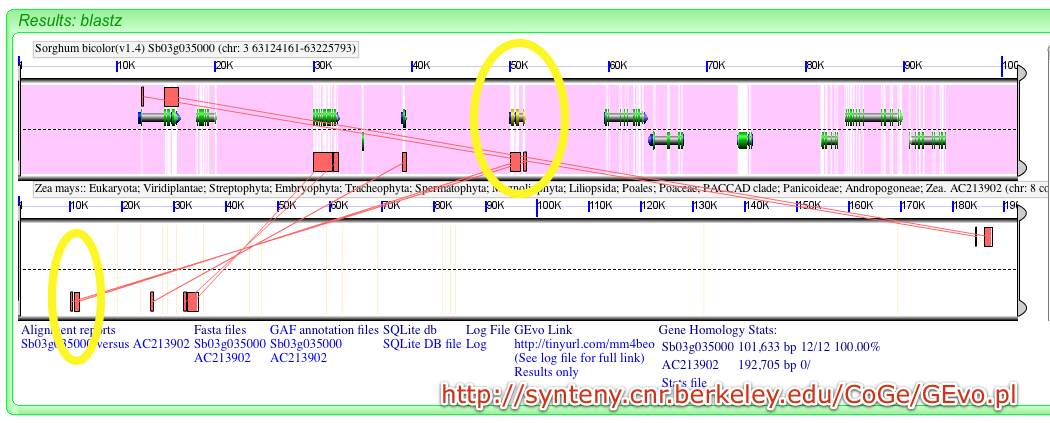
- In the resulting multi-alignment window (see above), shift-click on any highlighted region representing sequence similarity across genomes, to view all similarity relationships.
Thanks to Eric Lyons at CoGe for help in configuring the GEvo links.
Additional information
- The maizesequence.org website provides information on the maize BAC sequencing pipeline and classification of BACs.
- The AcDS Tagging project page at PlantGDB provides additional details on the Ac/Ds project, additional resources for sequence analysis, and instructions for requesting seed.
- A Ds Alignment table dedicated to display of fDs matches to maize BAC sequence, also updated daily, is available at ZmGDB.