Genome Browsers at PlantGDB
Overview
What are Genome Browsers?
PlantGDB provides genome browsers using the xGDB* platform, for plant species whose genomes have been completely or partially sequenced (see table below). These genome browsers provide high quality spliced alignments of available transcripts as well as predicted proteins from related model species. Additional alignments (e.g. microarray probes, genome survey sequence) may also be displayed, depending on the species. Other xGDB features include sequence analysis tools, data download, DAS services and community annotation.
The genome browsers are named by their Genus/species abbreviation (e.g. AtGDB for Arabidopsis thaliana). More information about individual Genome Browsers is available (see grey box at top of this page).
This Help Page provides a comprehensive description of features common to all xGDB browsers. Refer to Help Topics and Subtopics on the menu tree at left. In-text links to a related Help topic are green. Links to PlantGDB pages and external links are blue.
* xGDB = eXtensible Genome Data Broker, an open-source software infrastructure for integrated evaluation of genome features; see Schlueter et al, 2006.
Genome Browsers at PlantGDB (Video Demo; 6 min 17 sec)
- Quicktime
- Flash
- (Download)
The xGDB Web Interface
xGDB Genome Browsers provide an easy-to-navigate Web interface for each plant genome. See screenshot below for a summary of xGDB interfaces. Although there are a few differences depending on whether the browser is chromosome- or BAC/Scaffold-based, key features shared by all Genome Browsers include:
- GDB Home Page for each genome with a variety of links to data and sources.
- The top menu bar, a key feature of the Home Page, which has both Search and Tool Launch functions.
- Genome Context View (or BAC/Clone/Scaffold Context View) page showing a region of the genome with spliced alignments displayed as track glyphs.
- Sequence Record page, displaying sequence data for a transcript, predicted protein or other aligned sequence, with links to BLAST and other analysis tools.
- Transcript View, showing base level alignment and quality data within a selected genomic region
- Web Tools including BLAST and GeneSeqer, and a download site for sequence and database data.
- Community Annotation page and yrGATE annotation tool for contributing gene models.
- GAEVAL (Gene Annotation and Evaluation) tables for flagging inconsistent gene models.
- Protein Alignment Table table listing all spliced aligments to model species proteins.
- Data Download page containing all sequence data as well as a copy of the MySQL database.
- Advanced Search feature with options for retrieving upstream and downstream regions of a gene model or aligned sequence.
Species and Data Sources
Data sources are diverse. For partially sequenced genomes (BAC and BAC-sized sequences), GenBank HTG sequences are used. For assembled genomes, pseudochromosome or scaffold sequences are retreived from a specific Genome Repository, along with gene models and predicted proteins. Transcripts (EST and cDNA) are downloaded from GenBank, and transcript assemblies ("PUTs") are from PlantGDB's EST assembly repository.
The table below lists the genome browsers currently available at PlantGDB, together with genome data sources and versions. Not listed in this table are EST, cDNA and transcript assembly (PUT) data, which are common to all xGDB. Click any GDB link in column 1 to visit the xGDB Genome Browser Home Page; Click on the link under Source/Assembly or Gene Models to visit the corresponding Genome Repository external web site.
Genome Browsers at PlantGDB
| GDB | Species | Name | Type | Source/ Assem. | Gene Models | Protein Align |
|---|---|---|---|---|---|---|
| AtGDB | Arabidopsis thaliana | Thale Cress | Chromosome. | TAIR10 | TAIR10 | Rice |
| BdGDB | Brachypodium distachyon | Brachypodium | Chromosome. | Bradi1.2 | Bradi1.2 | Rice, Sorghum |
| BrGDB | Brassica rapa | Mustard | Chromosome. | Arabidopsis | ||
| CpGDB | Carica papaya | Papaya | Scaffold. | GenBank | GenBank | Arabidopsis |
| CrGDB | Chlamydomonas reinhardtii | Chlamydomonas | Chromosome. | JGI4.3 | JGI4.3 | Arabidopsis, Medicago |
| CsGDB | Cucumis sativus | Cucumber | Scaffold. | JGI | JGI | Arabidopsis, Medicago |
| GhGDB | Gossypium hirsutum | Cotton | BAC. | GenBank | GenBank | Arabidopsis |
| GmGDB (Chromosome) | Glycine max | Soybean | Chromosome. | Glyma1 | Glyma1 | Arabidopsis, Medicago |
| GmGDB (BAC/Scaffold) | Glycine max | Soybean | BAC/Scaffold. | Glyma0.1b | Glyma0.1b | Arabidopsis, Medicago |
| HvGDB | Hordeum vulgare | Barley | BAC. | GenBank | GenBank | Rice |
| LjGDB | Lotus japonicus | Lotus | Chromosome. | Lj1.0 | Lj1.0 | Arabidopsis |
| MeGDB | Manihot esculenta | Cassava | Scaffold. | JGI4.1 | JGI4.1 | Arabidopsis |
| MgGDB | Mimulus guttatus | Mimulus | Scaffold. | JGI1.1 | JGI1.1 | Arabidopsis |
| MtGDB | Medicago truncatula | Barrel medic | Chromosome. | Mt3.5 | Mt3.5 | Arabidopsis |
| OsGDB | Oryza sativa | Rice | Chromosome. | MSU 7.0 | MSU 7.0 | Arabidopsis, Sorghum |
| PpGDB | Physcomitrella patens | Moss | Scaffold. | Phypa1.6 | Phypa1.6 | Arabidopsis, Rice |
| RcGDB | Ricinus communis | Ricinus | Scaffold. | TIGR/JCVIv0.1 | TIGR/JCVIv0.1 | Arabidopsis |
| PeGDB | Prunus persica | Peach | Scaffold. | JGI1.0 | JGI1.0 | Arabidopsis |
| PtGDB | Populus trichocarpa | Poplar | Chromosome. | Ptr2.2 | Ptr2.2 | Arabidopsis |
| SbGDB | Sorghum bicolor | Sorghum | Chromosome. | Sbi1.4 | Sbi1.4 | Rice |
| SiGDB | Setaria italica | Foxtail millet | Scaffold. | 1.0 | 1.0 | Sorgum, Rice |
| SlGDB | Solanum lycopersicum | Tomato | BAC. | GenBank | GenBank | Arabidopsis |
| StGDB | Solanum tuberosum | Potato | Chromosome. | 3.4 | 3.4 | Arabidopsis, Medicago |
| SmGDB | Selaginella moellendorffii | Spike Moss | Scaffold. | JGI | JGI | Arabidopsis, Medicago |
| TaGDB | Triticum aestivum | Wheat | BAC. | GenBank | GenBank | Arabidopsis |
| VcGDB | Volvox carteri | Volvox carteri | Scaffold. | JGI | JGI | Arabidopsis, Medicago |
| VvGDB | Vitis vinifera | Wine Grape | Chromosome. | Genoscope | Genoscope | Arabidopsis |
| ZmGDB (Chromosome) | Zea mays | maize | Chromosome. | 5a.59 working | 5a.59 working | Rice, Sorghum |
| ZmGDB (BAC) | Zea mays | maize | BAC. | GenBank | GenBank | Rice, Sorghum |
Alignment Methods
Genome browsers display several types of alignment data, with specific matching algorithms and tools used for each type:
- Spliced alignment to same-species transcripts (EST, cDNA, PUT) using GeneSeqer
- Spliced alignment to heterologous predicted proteins using GenomeThreader
- Alignment of microarray probes based on PUT assembly match with VMatch
- Alignment to genomic sequence including Genome Survey Sequence (GSS) contigs (maize, sorghum), repeat masked regions (maize), or transposon flanking regions (e.g. maize-fDs sequence)
Web Tools (BLAST, etc.)
PlantGDB's genome browsers provides tools for analysis of sequences viewed or retrieved from the genome browser interface. In many cases when the tool link is clicked, the query sequence (a genomic region, or a transcript sequence) is automatically passed to the tool interface. Tools include:
- BLAST analysis with datasets that include genomic sequence, EST, cDNA, PUT, protein, and probe. Available from the Top Menubar or each genome browser.
- GeneSeqer spliced-alignment tool with four splicing models. Available from the Top Menubar from Home Page or Context View. If in Context View, GeneSeqer will query the current genomic region.
- Individual Geneseqer alignments for any splice-aligned transcript can also be viewed from the Sequence Record page.
- Similar to the above, the GenomeThreader spliced-alignment of any displayed protein sequence can be viewed from the Sequence Record page.
Data Import/Emport
xGDB Browsers can display data from another genome browser using Distributed Annotation Service (see DAS client). Similarly, xGDB tracks can are made available in DAS format for viewing remotely on other Genome Browsers (see DAS Server).
Quick Start
- To access any genome browser home pages:
- go to Projects - Genome Browsers on the PlantGDB menubar and select a genome database.
- Alternatively, any genome browser can be accessed by adding the four-letter database name to the PlantGDB URL, i.e. http://www.plantgdb.org/AtGDB.
- To view a genome region with spliced
alignments, select a genomic region or a
sequence ID to view:
- To view a region, select a genomic segment (chromosome, BAC, or Scaffold) and region (left and right coordinates), and click 'Go'. For example, select Chr='3' and Start='100,000', End='110,000'.
- Alternatively, enter a sequence ID (EST, cDNA, PUT, probe or other aligned sequence) in the Search window and press 'Genome' to view in genome context
- To view sample region, enter 'Go' using the default coordinates and genomic segment.
- The previous action will open a Genome Context View with aligned sequence and gene models displayed as color-coded glyphs.
- Controls available from this window
include:
- Navigate throught the genomic region by clicking Scroll (arrows) or zoom (boxes) tools
- Change track order/visibility using upper right controls
- Change track ID font size using left radio buttons.
- Further analysis available from Genome
Context View window includes:
- View sequence information: Hover over a track glyph
- View a Sequence Record for any track: Click on the track glyph
- Open a base pair level view of the region: click 'Transcript View'
- BLAST the genomic region using GDB-specific BLAST tool: Click 'Blast Genomic Region'
- Annotate a gene using the yrGATE tool: Click 'yrGATE'.
- Copy a link to return to the same region: right-click the 'Link to this Page' link at the lower right.
- Perform spliced alignment of a sequence dataset to the genomic region: click GeneSeqer link
- From the Sequence
Record view, the following actions can be
taken:
- For EST, cDNA, PUT: Check spliced alignment using GeneSeqer
- Open a BLAST window
- View a PlantGDB sequence record: Click 'PlantGDB'
- Link to external record (GenBank, TIGR, etc.) : click under 'Additional Resources'.
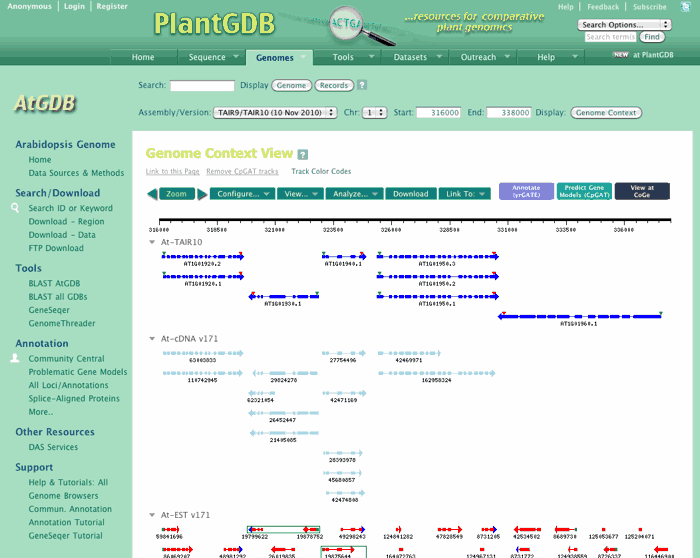
The Genome Home Page
Overview
The Genome Browser Home Page provides a standardized interface for each genome annotated at PlantGDB, plus information and links specific to that genome. Key features include:
- (some genomes) A dropdown menu to allow previous genome assemblies to be viewed (third row)
- A search window to retrieve spliced-alignments by entering a sequence ID
- A dropdown menu or menus for choosing genomic segment and start/end coordinates.
- A Login ID for Community Annotation users.
- A left menu bar with links to genome browser-specific resources and tools
- A right menu bar with links to external genome resources
A typical GDB Home Page is shown below . Details on menu functions are described in the following sections.

Choose Genome Assembly
For chromosome-based browsers that have undergone updates to their genome assembly, earlier genome versions can be viewed, along with their splice-aligned data, by selecting a previous genome version from the dropdown menu, .eg. Arabidopsis Genome Assembly: TAIR v.6.0.. Note that, although annotations can be viewed for any version, ONLY the current version can be used to add new annotations via yrGATE.

Search by ID
To search for a sequence (EST, cDNA, protein, probe) to the genome, enter the GenBank ID (gi or accession) or other ID in the Search window. Press "Genome" to return a Genome Context view of the sequence alignment. "Record" to return the individual xGDB Sequence Record.
For multiple sequence searches and keyword searches, use the Advanced Search tool.
Select Genome Region
xGDB browsers store genomic segments by ID number, which can be either chromosome number, scaffold number/ID, or GenBank gi or GenInfo Identifier. Alignments are stored by base pair location (Start/End) on the genomic segment.
Each Genome Browser is set to display a default genomic segment and location (Start/End coordinates), shown in the Home Page upper menubar. Press 'Go' to launch a Genome Context View window of this region. Alternatively, select a different genomic segment from the dropdown windown, type new Start/End coordinates and press 'Go'.
Several xGDB databases with very large genomic segment numbers (e.g. ZmGDB and CpGDB) provide tabular lists of genomic segments instead of a dropdown. Use your browser Search function to find a gi.
Menubar Links
- Top Menu: Sequence Retrieval, including Search by ID/Keyword, Search by Region, and Download All.

- Side Menu: Tools links: BLAST, GeneSeqer
- Additional Resources, including Data and Methods (detailed information on each Genome DB) and Splice-Aligned Protein Table, All Loci/Annotations table
- Support, including Help Pages (such as this one!) and tutorials
- Projects - Research applications and supplemental data from publications

The right sidebar link include external sites of interest for each genome.
Community Annotation Login
Left and right on the top menubar are links to the Community Annotation Central Login/Registration screen. Community Annotation Central is a repository for user-submitted annotations done via the yrGATE tool, and registered users can contribute annotations in any genome database. After curation, the annotations will be published on the genome browser. For more information visit the Community Annotation Help pages.
Downloads
The xGDB Download page provides complete data records for each current genome database. Link is on the left menubar. Files available include (where XX is Genus/species abbrev):
- XXgenome.bz2 - Complete genome sequence used in the current GDB version
- XXcdna.bz2 - All cDNAs splice-aligned to the genome
- XXest.bz2 - All ESTs splice-aligned to the genome
- XXpep.bz2 - All Heterologous protein sequence splice-alligned to the genome
- XXput.bz2 - All Heterologous protein sequence splice-alligned to the genome
- XXGDB165.sql - MySQL Data Dump for the current GDB version (e.g. version 165)
Genome Context View
Overview
The Genome (or BAC or Scaffold) Context View provides a graphical representation of a genomic region, with gene models and all aligned sequences represented by color-coded tracks (glyphs) arranged linearly across the region. The glyphs show regions of alignment with genome (exons) as thick bars and spliced-alignment gaps (introns) as narrow lines. Each glyph is hyperlinked to a Sequence Record page for further analysis
The Genome Context View also contains scroll/zoom controls to modify viewing scale and coordinates, a Transcript View window for base pair-level analysis, and links to yrGATE tool for Community Annotation.
Genome Context View is accessed from the GDB Home Page. For each Genome Browser, a region has been pre-selected for convenient viewing if you just want to browse the genome. To try it, open a new window showing the AtGDB Genome Browser Home Page. Then click 'Go' in the blue bar to view a region of chromosome 1, from 1 to 10001.
A typical AtGDB Genome Context view is also shown in the screenshot below.
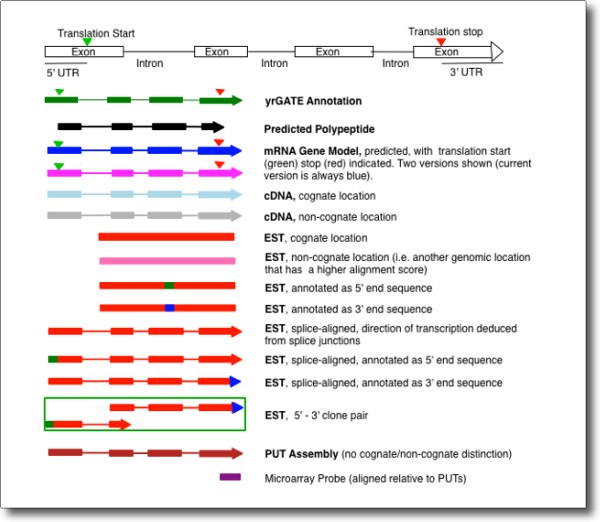
Track Types
Track images or "glyphs" are color coded according to sequence data type, and (for certain types) according to whether they are aligned at a cognate or non-cognate location. Directionality as deduced from splice junctions is indicated by an arrow, and introns are shown as a narrow line. Common data types are:
- yrGATE annotation (community-contributed): Green. Start/Stop codons are indicated by green/red triangle glyphs.
- Gene model: blue (and magenta if a second version is shown). Start/Stop codons are indicated by green/red triangle glyphs.
- Protein: black (and brown if a second species is shown)
- cDNA: light blue (cognate) or gray (non-cognate)
- EST: red (cognate) or pink (non-cognate)
- PUT assembly: dark red
- Microarray Probe: Purple
EST glyphs (red) also also display color codes based on sequence information
- green container around 2 glyphs: clone pair
- green box: 5' end sequence
- green box: 3' end sequence
For some genome browsers (e.g. ZmGDB), additional track types are shown.
- GSS alignments: yellow
- fDs: magenta
- Repeat mask regions: grey
Click below to view a figure summarizing track type information.
Track Controls (Hide/Drag-Drop)
Tracks can be hidden by clicking the down-arrow image at the left of each track name. Clicking again re-shows the track. Tracks can be moved by simply dragging and dropping in a new vertical location. Use the cursor to and click and hold anywhere in the track image, drag the image using your mouse, and let go in the new desired location.
Submenu
The Genome Context View's submenu provides access to various controls and context-sensitive menu options such as Base Pair Level View, Blast, GeneSeqer, GenomeThread, and yrGATE. Also provided are buttons to link to external databases such as CoGe. More information is available by clicking the Genome Context View Help icon.
Scroll/Zoom Region
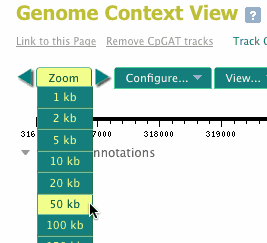
To scroll the Genome Context View to an adjacent region, click the left or right arrow in the Scroll/Zoom tool. A single click will advance the view by an amount equivalent to 50% of the current viewing region. NOTE: Don't click the arrow twice in rapid succession, as this will cause an error in the scrolling. Wait until the screen has refreshed to click again. To make larger changes to the region, enter new coordinates directly the Start: and End: windows in the top menubar.
To display a larger or smaller region of the genome, use the Zoom tool above the genome track. Ranges from 1 kb to 150 kb can be selected with a single click, and the resulting view will be centered on the current view. Additional adjustments in region can be made with the Start: and End: windows in the top menubar. NOTE: It is not recommended to view more than 150 kb as the data may take an excessive amount of time to load.
Sequence Description
Positioning the cursor over a track glyph results in the display of additional information about the track in the central Description window. This information typically corresponds to the functional annotation for a gene model, and for cDNA and EST the description is the GenBank description field.
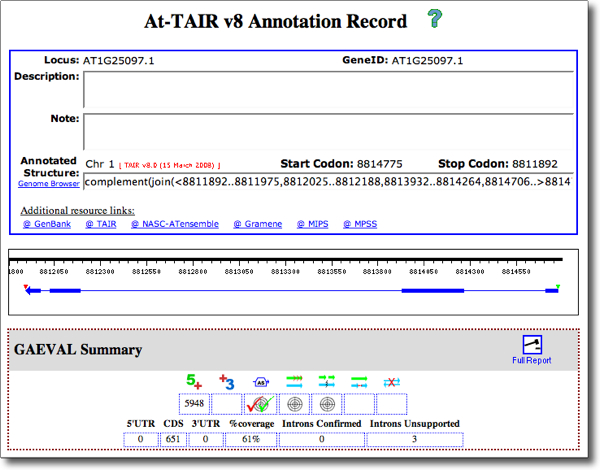
GAEVAL Flags
GAEVAL (Gene Annotation Evaluation) detects inocongruence between gene models and evidence alignments. Select 'Track Options → Show Flags' from the Gene Model Track Title (e.g. AtTAIR10):
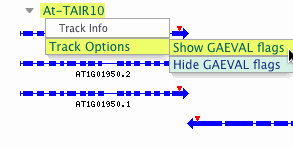
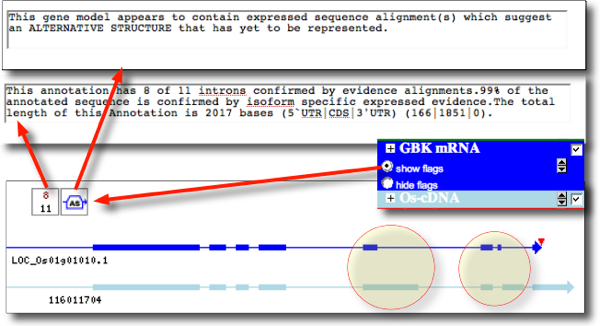
...and GAEVAL data and icons are presented immediately above the track glyph, and explanations are available in hover-over comments. Clicking on a GAEVAL glyph opens a report for that item.
See GAEVAL Tracks example in the screenshot below (based on a region of OsGDB Chr.1), the icons indicate that:
- Only 8 of 11 introns are supported by evidence;
- There is evidence for alternative splicing, confirmed by comparing the gene model (dark blue) with cDNA track (light blue).
For more information on how GAEVAL data are generated and interpreted, see 'Using GAEVAL' and 'GAEVAL Technical Description' in the Annotation Help Page.
Get Sequence Record
Clicking on a track glyph opens a Sequence Record View of the track.
How to Copy a Link to a Genomic Region
If you want to bookmark or otherwise retain a link to a specific genomic region, a link is provided in the upper right portion of the Genome Context View window ("Link to this Page"). Right-click the link and select "Copy Link Location".
Web Tools
Sequence analysis/retrieval tools (Advanced Search, BLAST and GeneSeqer) are available from the top menubar of any GDB Home Page. In Genome Context View, additional tools are available that utilize the currently viewed genomic region as the input for tool processing ( Display Genomic Region, BLAST Genomic Region, Transcript View, yrGATE). Each tool is described in more detail below.
Advanced Search
The Advanced Search window is accessed from the 'Search ID/Keyword' link in the Left menu bar of each GDB. Advanced Search provides powerful features for finding genes or aligned sequences, groups of sequences, or functional annotations. In addition, the search results page provides a variety of options for sequence retrieval including upstream or downstream sequence, introns, exons, or complete spliced transcripts. See screenshot below to view Search interface.
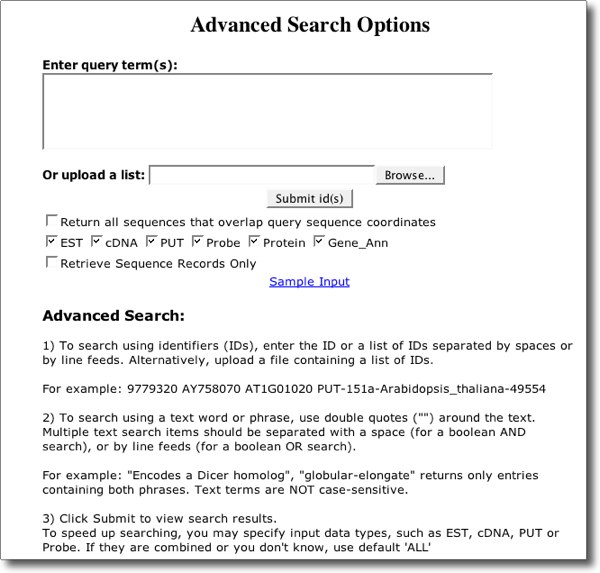
To use the Advanced Search, do the following:
- Open an Advanced Search window in the genome browser of choice, e.g. AtGDB. Brief instructions are provided on the Search page itself.
- Enter one or more search terms in the query window (try one of the examples provided). Note that text terms can be searched using quotes.
- Several options for output can be chosen:
- To capture all overlapping sequences with a single query, click 'Return all sequences that overlap query sequence coordinates'. This is especially useful to retrieve an overlapping set of ESTs, or to retreive other sequences (e.g. aligned proteins) not specified in the query.
- To speed searching, you can specify one or more sequence types to search: EST, cDNA, PUT, Probe, Protein, Gene_Ann. By default, all are checked.
- If you don't need to view the gene models and other information in the output, click 'Retrieve Sequence Records Only' If this box is checked, your results will be one or more FASTA-formatted sequence files only.
- Click 'Submit ID(s)'. The results are displayed as a list of matching sequences with genomic coordinates and a graphic view of the gene model
- To view a retrieved sequence in Genome Context, click the track glyph.
- To retrieve nucleotide sequence
corresponding to the splice-aligned region
defined by a retrieved sequence, and/or the
original queried sequence, do the following:
- Click the 'Select' checkbox(es) as appropriate
- Select one or more of the options for sequence retrieval (see screenshot below).
- To avoid retrieving portions of adjacent, transcribed regions, select 'Exclude neighboring gene seq.'. This will mask any region where another sequence is aligned.
- To hide any sequence type from the output, click the appropriate button (Hide EST, Hide cDNA, Hide PUT, Hide Probe, Hide Protein, Hide Gene_ann).
The screenshot below shows the sequence retrieval options available.

Download Region
You can download genomic sequence, gene models or transcript (EST, cDNA, PUT) for any region in Genome Context View by selecting 'Download' on the GDB submenu, or 'Download - Region' in the Left menubar. Click to select data type to download, and click 'Display Sequence for Download'.
BLAST Genomic Region
The current genomic region can be sent to a BLAST page (xGDB BLAST) by clicking BLAST@XxGDB' in the upper menubar. This opens a new window with BLAST options. Choose a database to search from the dropdown menu.
Transcript View (See also below)
Transcript View allows you to view the actual base-pair level alignment across a region, for all transcripts and/or proteins. Using the Start/End window, optimize the Context View of the region you want to evaluate, and click the "Transcript View" link. This opens a new window with base pair alignment views and scores for all of the spliced alignment tracks. See below for more information on using the transcript view window to explore spliced alignment data.

yrGATE tool for Annotation
The yrGATE tool allows users to annotate genes from any genome browser. To annotate a gene in the currently viewed region in Genome Context View, click the 'yrGATE' link above the scroll/zoom tool. Note that you must be a registered user and be logged in to save an annotation. For detailed information on Community Annotation and the yrGATE tool, see Community Annotation help.
DAS Client/Server Tools
PlantGDB provides the ability to view Distributed Annotation Server (DAS)-served data directly on an xGDB genome browser. For example, you could display TAIR gene models provided by www.arabidopsis.org directly in the AtGDB genome browser at PlantGDB. For detailed information see DAS Client section below.
Users can also view xGDB Genome Browser track alignments on a remote Genome Browser such as GBrowse or Ensembl using the DAS Server links provided. For example, you can view AtGDB's GeneSeqer spliced alignments on the Ensembl browser at atensembl. For detailed information see DAS Server section below.
Sequence Record Page
Overview
Sequence Record: Each aligned sequence type (EST, cDNA, PUT, Probe, etc.) has its own Sequence Record page. The Sequence Record page displays useful information for every spliced-alignment of a sequence in a GDB. The Sequence Record Page includes:
- Sequence data and metadata (FASTA-formatted sequence, GenBank description, etc.).
- A table showing all genomic alignment coordinates (loci) and associated gene structure for all alignments of the sequence in the genome.
- Links to additional analysis tools (BLAST, spliced alignment) and resources (see details below).
Annotation Record: For gene models displayed in xGDB browsers, a similar page called "Annotation Record" is used to display key information (Description, Notes, Annotated structure, and links related data sources. The Annotation Record page also displays information about any incongruence between the gene model and splice-aligned transcripts, using what is called a GAEVAL (Gene Annotation Evaluation) report.
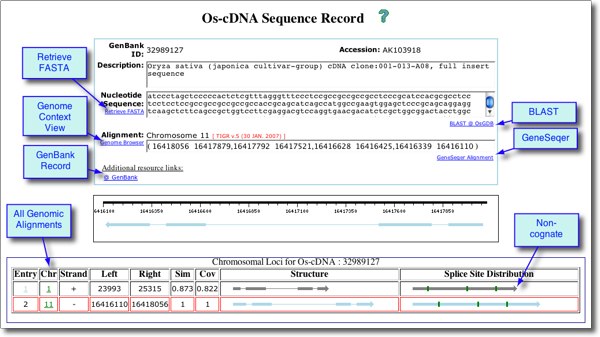
A screenshot of a typical Sequence Record is shown below. To view the actual record, launch OsGDB and paste GI 32989127 into the Search window and click 'Records'.
A screenshot of a typical Annotation Record is shown below. To view the actual record, launch OsGDB and paste AT1G25097.1 into the Search window and click 'Records'.
Accesssing Sequence Records
A Sequence Record page can be accessed in one of two ways:
- From the Genome Context View, click on any track glyph.
- From either the GDB Home Page or Genome Context View, enter a sequence ID in the Search window and click on the 'Records' button.
- From the Advanced Search window, enter one or more sequence IDs and click 'Submit Query'. From the Results window, click on a track glyph to launch Sequence Record view.
Other features: Genomic Loci, Spliced Alignment, BLAST, Link to PlantGDB
Other features available in Sequence Record View are detailed below.
Genomic Loci Table: Some sequences align to multiple genomic locations, and if so these will be displayed in tabular format, with genomic segment ID (chromosome, BAC, Scaffold number) listed in column 2 along with strand, coordinates, similarity score and structure/splice distribution.
- To view any alignment in Genome Context View, click the ID number in column 2.
- To view the Sequence Record for an alternate genomic alignment location, click the Item Number (column 1)
Spliced Alignments: The Sequence Record View also serves as a portal for viewing detailed spliced alignment data generated by GeneSeqer (for cDNA, EST, PUT) or GenomeThreader (for protein). Clicking the right-hand link 'GeneSeqer Alignment' or 'GenomeThreader Alignment' opens a new window with detailed output from the alignment report. For example, paste the GI 16612276 into the Search window at AtGDB and then click 'Records'. From the Record View, click 'GeneSeqer Alignment' to view the report.
BLAST: To open a BLAST window with the current sequence as a query, click 'BLAST@XxGDB'. You can choose from a range of databases to query (depending on the GDB), including PUT, EST, cDNA, probe, genomic sequence, and heterologous proteins.
View PlantGDB Record: to view a PlantGDB version of the Sequence Record, click under Additional Resource Links: @PlantGDB. This opens a related sequence record with a sequence diagram (or alignment if PUT), plus various options for retrieving sequence data. In addition, you can click 'BLAST@GenBank' to send the sequence to NCBI for BLAST analysis to any of NCBI's databases, or BLAST@PlantGDB to send the sequence to PlantGDB's comprehensive BLAST tool.
Base Pair Level View
Overview
Base Pair Level View allows you to view the actual base-pair level alignment across a genome region, for all transcripts and/or proteins aligned to that region.
The Base Pair Level View window contains four types of information in quadrants: Data, Tracks, Track IDs and Sequences. See see screenshot below. All track types (gene model, protein, cDNA, EST, PUT) are show in top right, and sequence for all except gene models is displayed below. Linking the two is a zoom reticule controlled by a horizontal scroll bar, allowing the user to focus on any region in the current genome region. Vertical scroll bars allow long lists of tracks to be browsed.

Launch Base Pair Level View
Starting in Genome Context View, adjust the Start/End coordinates to span the genomic region you want to view. Then select "View → Base Pair Level " from the submenu (see screenshot below). This opens a new window with base pair alignment views and scores for all of the spliced alignment tracks.
NOTE: Base Pair Level View is optimized for viewing genomic regions spanning 10,000 bp or less.
Graphic Alignment Region
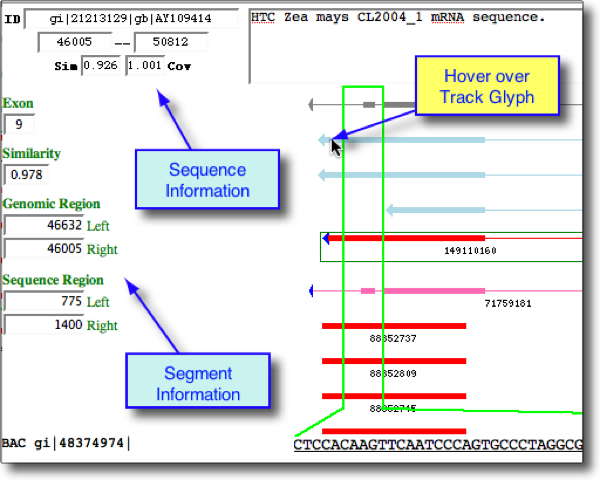
The top region of Base Pair Level View presents a graphical view of a genomic region, with all track types displayed in their splice-aligned context. Hover over a track glyph to display information about that region and its alignment on the genome. See screenshot below. Data displayed includes:
- Sequence information (in black, above): ID, coordinates, similarity, coverage, description
- Segment information (in green, below): Exon number, similarity, genomic coordinates, sequence coordinates.
A scrolling zoom window allows any region in the graphic alignment region to be viewed at the base pair level. The position of the zoom window (green lines) is controlled by a horizontal scroll bar (see screenshot below). Adjust the position of the bar to coincide with a region of interest contained within the zoom window. Any tracks appearing in that window will have their base pair (or amino acid) sequence displayed below (see next section). You may have to scroll vertically to view sequences that are off screen due to large number of alignments
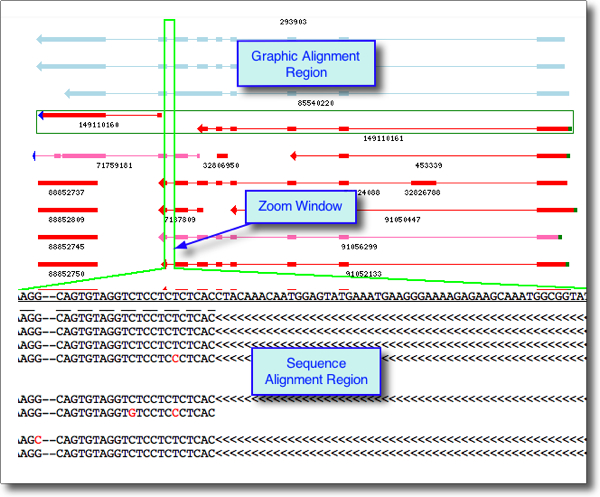
Sequence Alignment Region
In the lower half of Base Pair Level View, all transcript and proteins sequences are displayed with their sequence ID on the left and their alignments relative to the genomic sequence, in a region specified by the zoom window described above. This window allows close inspection of the spliced alignments details for multiple sequences at once.
- Intron regions (gaps) are displayed by directional angle brackets ">>>>>" for sense strand, "<<<<<" for antisense.
- Base pair gaps are indicated with a dash ("-")
- Base pair differences from genomic sequence are shown in red.
Hints for using Base Pair Level View
- To identify a graphic alignment that corresponds to a given sequence, hover over the sequence ID in lower left. The corresponding graphic will be highlighted with a dotted border.
- If you want to hide one or more sequences from the alignment, click on the corresponding graphic (glyph) and select "Hide in Alignment" in the resulting dialog box. The same process can be used to show a previously hidden sequence.
- To retrieve FASTA sequence or view the Sequence Record View for a sequence, click on the graphic and select the appropriate action from the resulting dialog box.
- You can resize the window using your browser handles in order to view more or less sequence. The screen will take a moment to refresh when you do this.
What is DAS?
DAS (Distributed Annotation System) provides a method for retrieving remotely-served data specific to a genome region, such as "All annotations in the range of 10-20kb on Arabidopsis chromosome 1". DAS queries can also limit the types of annotations that are returned, such as "only EST_alignments in the range 10-20kb on Arabidopsis chromosome 1".
There are two components required for DAS to operate:
- A DAS server provides a means to deliver DAS data over the internet to any genome browser capable of interpreting and displaying the data format appropriately. All xGDB browsers are configured to serve one or more datatypes.
- A DAS client receives, interprets and displays data served by a DAS server. All xGDB genome browsers can display DAS-served data if a source is available.
For a list of DAS services for each genome at PlantGDB, refer to the DAS Overview Page.
Adding tracks at PlantGDB using the DAS Client
If you wish to view alignments from another genome browser at PlantGDB, the DAS client can be used.
To add a DAS track, first select desired genome segment and coordinates from the GDB Home Page and click "Go", then select menu item "Configure -> Add Track" and paste in the appropriate DAS URL. Then click "Validate URL" and then select a DAS resource from the options that appear. Click "Add Track" and the new track should appear in the genome context window.
Viewing tracks remotely using DAS Server
To view PlantGDB genome alignments on another genome browser, first identify the appropriate URL for the genome data to be served using our DAS Sevices Table, and then follow the instructions on the remote browser for linking to this URL.
The following sections provides a step-by-step guide to displaying ZmGDB and AtGDB tracks on the TAIR8 genome browser on other browser platforms.
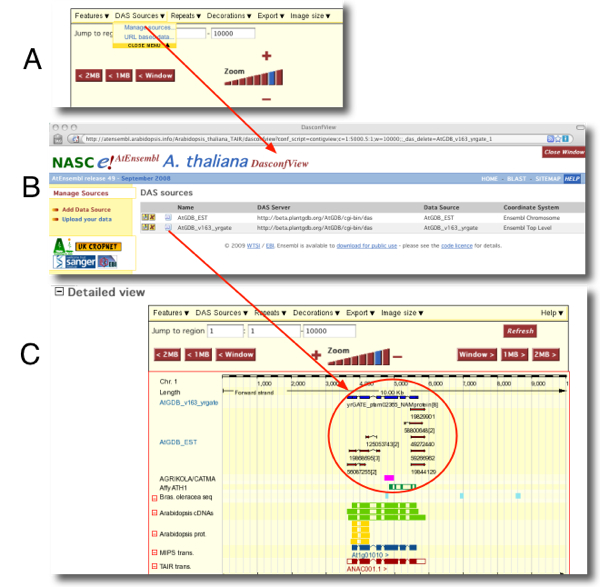
How to view AtGDB tracks on At-Ensembl
- Open a TAIR browser window at NASC Arabidopsis Ensembl
- Enter a chromosome and coordinates for a region you wish to view (e.g. chr 1, bases 1 to 10,000) and click "go"
- Under the "Detailed View" track region, click "DAS Sources" and select "Manage Sources" from the dropdown (see figure below, panel A)
- Click "Add Data Source" on the left menu
- The resulting window displays "Step 1 of 3". Now click "Enter Server" (to the right to the "DAS Server URL" dropdown)
- Paste the following URI: http://www.plantgdb.org/AtGDB/cgi-bin/das and click "NEXT"
- NOTE: At this point you may need to click the back browser button or click "PREVIOUS" in the DAS wizard to view the DAS sources correctly.
- On the lower part of the page you will see several DAS sources available from the AtGDB DAS server (see figure below, panel B). Select one of these by clicking the checkbox, e.g. AtGDB_v163_yrgate, and click "NEXT"
- Under "Sequence Coordinate System" select Ensembl Top Level; under under "Assembly Version select "TAIR8"; under "Enable on" select "contigview", if not already selected by default.
- You are now at Step 3 where you can customize the display for "AtGDB_v163_yrgate". For example, you can edit the track name and label if desired. NOTE: be sure to select "Yes" for "Group Features" and "Use Stylesheet". Change "Max Rows to Display" to "Unlimited" unless you want to limit the display.
- Click "Next" to end the DAS configuration session. Now, when you refresh the genome browser's "Detailed View", you should see AtGDB community annotation gene models displayed (see figure below, panel C).
Loci/Annotations Table
Overview
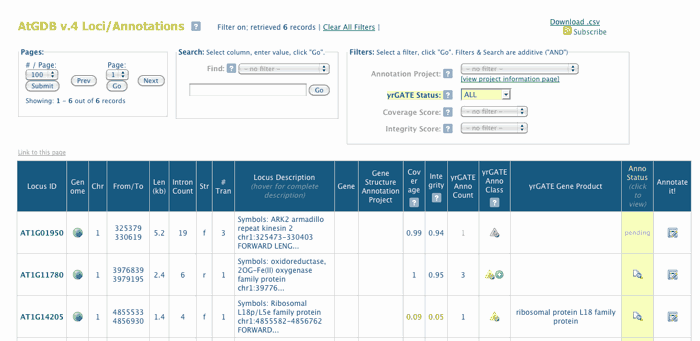
For each genome, loci have been assembled in tabular form along with additional information about that locus.
Powerful search and filter tools are available for querying the dataset, and users can link out to other genome views or re-annotate a locus using the yrGATE tool.
To access: Use the left menubar link "All Loci/Annotations ". The table displays each locus ID in chromosome or genome segment order (see screenshot below).
Search / Filter Tools
The Search tool allows queries based on any table column, plus specialized searchs, and the Filter tool provides specialized search filters (Projects, yrGATE Annotation Status)
- When filter is in effect, the column being filtered is highlighed yelloe
- Click Clear All Filters to clear search filters
- You can nest Search and Filter queries.
Projects
Projects are informal categories designed to facilitate annotation. Select a project from the Projects dropdown.
- Functional categories (e.g. "Kinases")
- Groups, such as classrooms
- Each genome has a default project in which all loci with high coverage/low quality and from 1-5 introns have been selected for re-annotation.
To view more information on projects for a genome, click 'View Project Information '.
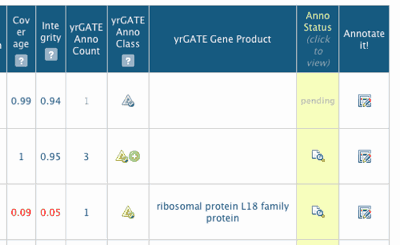
Links to Community Annotation
The Loci/Annotation tables at PlantGDB provide information and hyperlinks to the yrGATE tool for community annotation of gene structure.
- yrGATE Annotation Class is indicated by icons. Hover for explanation.
- yrGATE Annotation Status, either pending or public. If public, a "magnifier" icon will allow you to view the annotation.
- The last column has an Annotate it! icon. Click to launch a yrGATE annotation window to re-annotate the locus.
Splice-Aligned Proteins
Overview
For each genome, functionally annotated model species proteins from Arabidopsis, rice, Medicago or sorghum are splice-aligned to genomic DNA using the GenomeThreader program. While the protein alignments can be viewed graphically in Genome Context View, we also provide a Protein Alignment Table for browsing and searching alignments. This table organizes splice-aligned proteins and their functional annotations in linear order according to their start/end coordinates on a genomic segment. Using the included search tools, users can query for specific genes or functional annotations, across the entire genome or on a single genomic segment. The tables also provide hyperlinks to CoGe's GEvo (Genome Evolution) tool for multiple genome alignment.
The table query functions are described in detail in the following subsections. Refer also to the screenshot below showing a typical Protein Alignments Table.
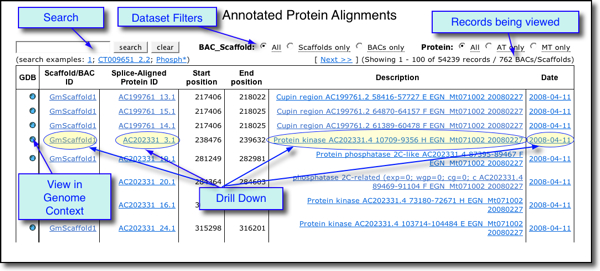
Data Sources
PlantGDB uses predicted protein sequences from (Arabidopsis thaliana, rice (Oryza sativa, Medicago sativa, or Sorghum bicolor) for spliced alignment. Functional annotations are those supplied by the respective genome and version.
To view protein data source and version, refer the xGDD Table in this Help document, or go to the Data & Methods link on any xGDB home page, accessible from the left menubar (for example, see the AtGDB Data and Methods Page.
Table Search / Data Filter
The Search window allows queries based on ID or keyword.
- Genome Region ID, depending on the genome
browser:
- Chromosome. Example: 2 (Note that you do not need to type "AtChr2"
- Scaffold ID. Example: 237 (Note that you do not need to type "GmScaffold237"
- BAC gi. Example: 191636786
- Protein ID. Example: LOC_OS09g12345
- Keyword. Examples: phosphate*; protein kinase
The Drill down: Clicking a specific Chromosome/Scaffold/BAC ID, Protein ID, Description or Date value in the table filters results according to that value.
Dataset Filters: For some GDB, radio buttons are provided to allow subsets of the data to be viewed:
- BAC/Scaffold: All / Scaffolds Only / BACS only
- Protein: (Species 1, e.g. AtPEP; Species 2, e.g. MtPEP)
- Show retrotransposons (ZmGDB)
- Show fDs (transposon insertions) (Zm GDB)
To perform a new search or clear the current search results, click 'Clear'.
Table Cell Click
In addition to the above, clicking in a table cell can perform one of two types of functions:
- View in GDB: Clicking the GDB icon in column 1 opens a new web page displaying the corresponding genomic region in Genome Context View
- Drill down:Clicking a specific Chromosome/Scaffold/BAC ID, Protein ID, Description or Date value in the table filters results according to that value.
To perform a new search or clear the current search results, click 'Clear'.
Links to CoGe's GEvo Tool
The Splice-Aligned Proteins tables at PlantGDB now provide hyperlinks to CoGe's GEvo (Genome Evolution) tool for multiple genome alignment. This allows easy exploration of colinearity across genomes.
- Choose a Region First, find a splice-aligned gene model of interest in the Protein Annotation Table (linked via the left menubar of each Genome Browser). You now want to explore upstream and downstream of this region for colinearity with model genomes.
- Check Alignment Complexity Notice the Start Position/End Position for this row. How many spliced alignments above and below overlap with these coordinates? It is usually best to choose a region with few overlaps for easier interpretation.
- Click the CoGe Link in Column 2 This opens a new browser tab/window and displays a series of genome entries within CoGe's GEvo (Genome Evolution) tool, corresponding to each overlapping gene model. The last entry will be the genomic region you are querying. If using a BAC-based genome, the entire BAC is loaded; if chromosomal, a 100K region centered around the locus of interest is loaded.
- Select Analysis Tool (or use default) Click the Algorithm Tab to select an algorithm for multi-genome comparison: BLastZ (large regions) [default] or another option, e.g. TblastX.
- Skip one or more sequences You can click "Sequence Options" to skip one or more model species sequences if you want to focus on a particular comparison to the genome of interest.
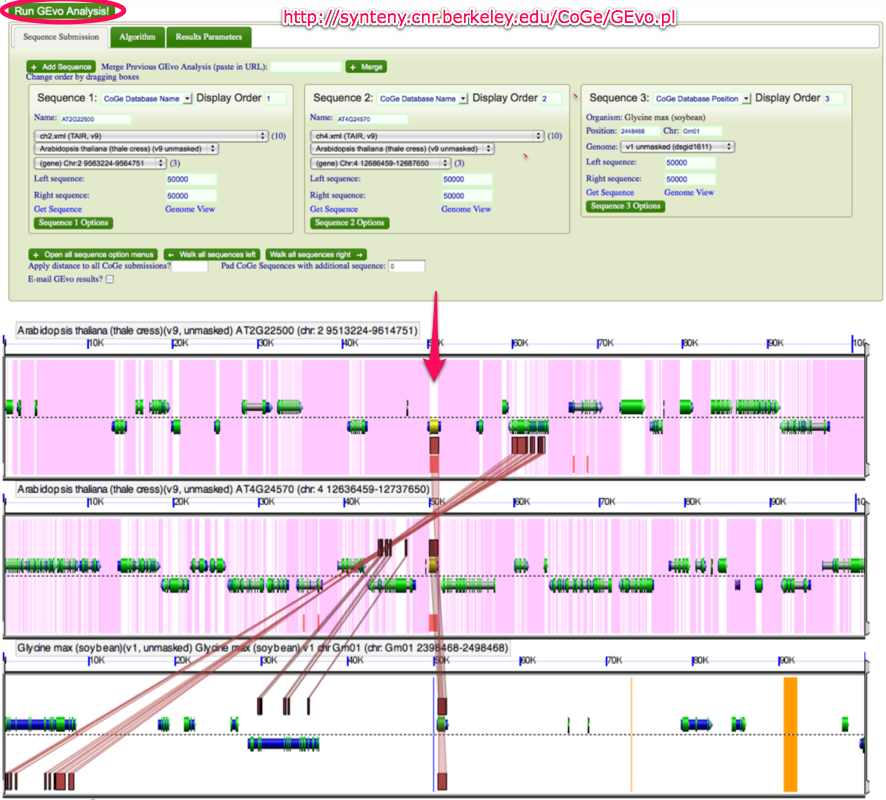
- Click "Run GEvo Analysis" This will bring up a multigenome alignment display with shaded regions representing homology between each genome. Click a shaded region to view connectors indicating homology pairing, or shift-click a shaded region to view ALL connectors. See CoGe's Help pages for more information.
The screenshot below shows an example from GmGDB in which two Arabidopsis chromosomal regions (Sequence 1 and Sequence 2, respectively) were aligned to Glycine max Chr1 2398468-2498468 (Sequence 3). This GEvo view is based on the spliced-alignment of Arabidopsis gene AT2G22500.1 to Glycine max Chr1 in the GmGDB Protein Alignments Table. To try this alignment, click to load the region data to GEvo, and then click "Run GEvo Analysis".